XGboost 全名為 eXtreme Gradient Boosting,是目前 Kaggle 競賽中最常見到的算法,同時也是多數得獎者所使用的模型。此機器學習模型是由華盛頓大學博士生陳天奇所提出來的,它是以 Gradient Boosting 為基礎下去實作,並添加一些新的技巧。它可以說是結合 Bagging 和 Boosting 的優點。XGboost 保有 Gradient Boosting 的做法,每一棵樹是互相關聯的,目標是希望後面生成的樹能夠修正前面一棵樹犯錯的地方。此外 XGboost 是採用特徵隨機採樣的技巧,和隨機森林一樣在生成每一棵樹的時候隨機抽取特徵,因此在每棵樹的生成中並不會每一次都拿全部的特徵參與決策。此外為了讓模型過於複雜,XGboost 在目標函數添加了標準化。因為模型在訓練時為了擬合訓練資料,會產生很多高次項的函數,但反而容易被雜訊干擾導致過度擬合。因此 L1/L2 Regularization 目的是讓損失函數更佳平滑,且抗雜訊干擾能力更大。最後 XGboost 還用到了一階導數和二階導數來生成下一棵樹。其中 Gradient 就是所謂的一階導數,而 Hessian 即為二階導數。
XGBoost 除了可以做分類也能進行迴歸連續性數值的預測,而且效果通常都不差。並透過 Boosting 技巧將許多弱決策樹集成在一起形成一個強的預測模型。
在這裡幫大家回顧一下整體學習中的 Bagging 與 Boosting 兩者間的差異。首先 Bagging 透過隨機抽樣的方式生成每一棵樹,最重要的是每棵樹彼此獨立並無關聯。先前所提到的隨機森林就是 Bagging 的實例。另外 Boosting 則是透過序列的方式生成樹,後面所生成的樹會與前一棵樹相關。本章所提及的 XGBoost 就是 Boosting 方法的其中一種實例。正是每棵樹的生成都改善了上一棵樹學習不好的地方,因此 Boosting 的模型通常會比 Bagging 還來的精準。
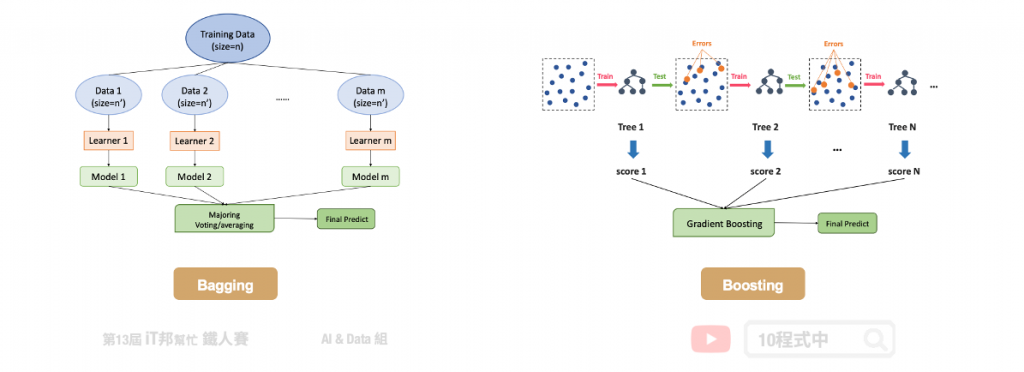
我們再與最一開始所提的決策樹做比較。決策樹通常為一棵複雜的樹,而在 Boosting 是產生非常多棵的樹,但是每一棵的樹都很簡單的決策樹。Boosting 希望新的樹可以針對舊的樹預測不太好的部分做一些補強。最終我們要把所有簡單的樹合再一起才能當最後的預測輸出。
AdaBoost 是由 Yoav Freund 和 Robert Schapire 於 1995 年提出。所謂的自適應是表示根據弱學習的學習誤差率表現來更新訓練樣本的權重,然後基於調整權重後的訓練集來訓練第二個弱學習器,藉由此方法不斷的迭代下去。
Gradient Boosting 由 Friedman 於 1999 年提出。其中 GBDT (Gradient Boosting Decision Tree) 的弱學習器僅限於只能使用 CART 決策樹模型,並採用加法模型的前向分步算法來解決分類和迴歸問題。
接下來介紹三個近年三個強大的開源機器學習專案。首先 XGBoost 最初是由陳天奇於 2014 年 3 月發起的一個研究項目,並在短時間內成為競賽中的熱門的模型。接著於 2017 年 1 月微軟發布了第一個穩定的 LightGBM 版本。它是一個基於 Gradient Boosting 的輕量級的演算法,優點在於使用少量資源、更快的訓練效率得到更好的準確度。另外在同年的 4 月,俄羅斯的一家科技公司 Yandex 發布了 CatBoost,其核心依然使用了 Gradient Boosting 技巧,並為類別型的特徵做特別的轉換並產生新的數值型特徵。

未來幾天將會介紹 LightGBM 與 CatBoost 哦!
Parameters:
Attributes:
Methods:
from xgboost import XGBClassifier
# 建立 XGBClassifier 模型
xgboostModel = XGBClassifier(n_estimators=100, learning_rate= 0.3)
# 使用訓練資料訓練模型
xgboostModel.fit(X_train, y_train)
# 使用訓練資料預測分類
predicted = xgboostModel.predict(X_train)
我們可以直接呼叫 score() 直接計算模型預測的準確率。
# 預測成功的比例
print('訓練集: ',xgboostModel.score(X_train,y_train))
print('測試集: ',xgboostModel.score(X_test,y_test))
輸出結果:
訓練集: 1.0
測試集: 0.9333333333333333
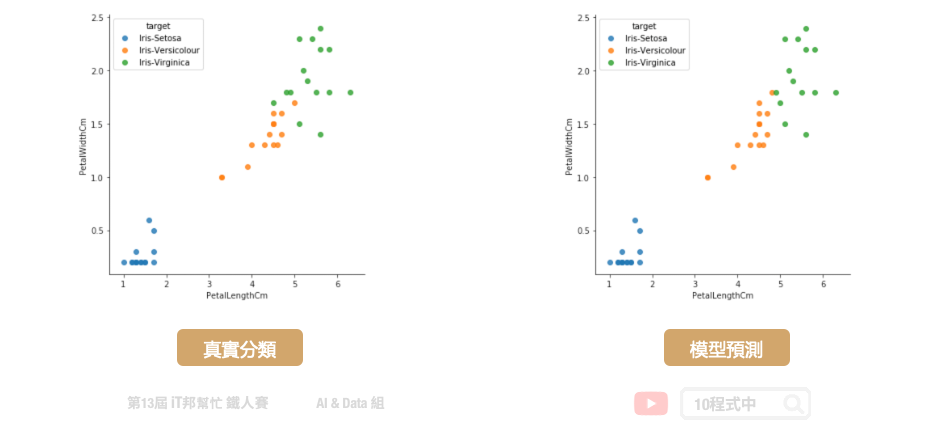
大家可以試著與前幾天的決策樹和隨機森林兩個模型相比較。是不是 XGBoost 有著更好的預測結果呢?因為有了 Gradient Boosting 學習機制,大幅提升了預測能力。在學習過程中將預測不好的地方,尤其是橘色 (Versicolour) 與綠色 (Virginica) 交界處有更好的評估能力。
Parameters:
Attributes:
Methods:
import xgboost as xgb
# 建立 XGBRegressor 模型
xgbrModel=xgb.XGBRegressor()
# 使用訓練資料訓練模型
xgbrModel.fit(x,y)
# 使用訓練資料預測
predicted=xgbrModel.predict(x)
文章同時發表於: https://andy6804tw.github.io/crazyai-ml/15.XGBoost/
如果你對機器學習和人工智慧(AI)技術感興趣,歡迎參考我的線上免費電子書《經典機器學習》。這本書涵蓋了許多實用的機器學習方法和技術,適合任何對這個領域有興趣的讀者。點擊下方連結即可獲取最新內容,讓我們一起深入了解AI的世界!
👉 全民瘋AI系列 [經典機器學習] 線上免費電子書
👉 其它全民瘋AI系列 —— 這是一個入口,匯集了許多不同主題的AI免費電子書
10程式中你好~
最近正再更新開發課演算法工程師的一些內訓資訊,需要補充一些集成學習目前較火紅的技術來當教材(教科書都2004年左右,有點過時),因此透過GOOGLE參考到10程式中你所提供的XGBoost資料,十分感謝你在機器學習領域中無私分享給大家(開放的資料)這麼豐富的寶貴知識(吸收至撰寫出都是時間成本)。
個人也提供一點補充如下:
Boosting 的優點誠如Hastie教授在其教科書中所寫的:提升方法串聯了許多弱分類器的輸出以產生有效” committee”的過程,這是十分有效的學習思想之一。
The motivation for boosting was a procedure that combines the outputs of many “weak” classifiers to produce a powerful “committee.”
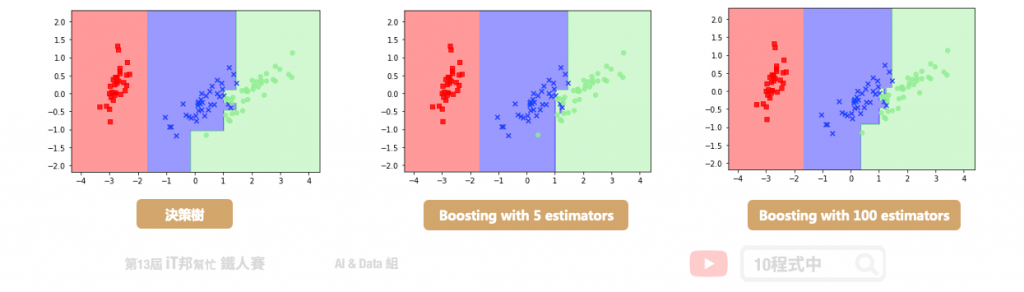
Boosting 的缺點也就因此而來,既然是一個委員會過程,那測試樣本必然就得「跑完全場」。這裡,直接以10程式作者所提供的圖1:決策樹來做說明。紅色類別只需要一個特徵就能被CART的分割度量所分出(直接到leaf層),而後根本不需要如串聯集成(圖1:boosting with 5 estimators; 圖1:boosting with 100 estimators)被硬性規定要往下一個委員(下一個弱分類器)跑。再譬如,分級結構(如:DAGSVM)允許我們對於效能不佳的某子樹(如多路分裂下的某個左子樹)進行改善,其它所有旁路分支根本不受影響,但串聯結構具有前、後節點依賴性,不允許抽出中段改完後再接回的情況;且當有新類別進來時又命中注定只能整個架構重新訓練(數據的一些改變將導致一系列完全不同的分裂,這不是高方差high variance,什麼是高方差?!),反觀分級結構這時候它有高機率只需根據新類別往哪分裂的子樹跑,去修改與新增該路徑下的所有辨識節點即可。
誠如在比較不同模型的優、劣時,除訓練階段開銷、測試準確度高低,還必須考量諸如優化超參數過程[註1]所花的時間…等等才具有客觀性,然若非是要發期刊,而是業界工作任務上的職責,那僅就測試階段的開銷,串聯結構有其上述先天結構上一條龍的特性,從事模式識別的工作者有必要「提前注意」自己所接的任務與專案是否分級結構(經典如:DAGSVM)、並行結構(經典如:Bagging)[註2]才是適合自己的選項,才不會花了好多時間優化而得的最終模型,卻敗在每筆測試樣本的測試時間過長(如:決策樹個數,80顆為驗證過的最優參數),跟它牌相比無法機台量產。
註1:林智仁教授的LIBSVM為例,
python grid.py backStatistic_Select_train.txt(訓庫資料)
grid.py採用交叉驗證獲得最佳參數C與g
最後,跟作者和將來在此留言討論的同好,我也分享兩點看法,若大家有空時也可以參考看看,希望能有所啟發:
對這類經典算法、優秀論文若能安插在工作時間上做實踐性的確認、複現表格上的實驗結果、享受過程的收穫非常重要是沒錯,但若該從事人員的團隊人數過少或沒有專業的專案經理(或研發長牛人),很難有機會「讀者自覺」論文中需要沈思與討論的地方,而就跟隨該論文作者的說法為說法(很少有期刊的作者會自己批評他演算法不足的地方,只會想辦法彰顯其優勢,沒有accept,一切都是如夢泡影),而喪失了以不同角度或思維轉變來享受從論文中獲取作者沒講到的其它沈思!
不要盲目認為存有複雜的公式推導(如:模糊積分分類器)和最新的辨識技術(2018~2022),用上去效果肯定突飛猛進,這種想法是有疑慮的。工作之餘我縱觀近10年期刊論文數十篇,諸多最新演算法的test performance相比經典原作落入2%的改善範圍比比皆是,這些靠著額外添加於SVM身上的理論(模糊、SN比、基因、貝葉斯…等)、額外添加於決策樹(Decision tree)身上的理論(標準非線性規劃理論上用於判斷某函數凹凸性的Hessian matrix,被引入Gini索引的分割度量…等)的期刊,有多少是為畢業、為升等而湊成,當某個火紅的新技術將你的訓練庫特徵空間劃分得破碎不堪時,就為追求計算score()模型預測的準確率,這時得去發問陽春的3-KNN是否就足以匹敵? 其實,這也是每位從事辨識演算法大家心照不宣的事實之一。
盡量中庸文字遣詞,若有冒犯或偏頗之意,還望大家多多包涵
感謝邦友worthwhilekimo的觀點分享!
確實在真實應用場景必須要在模型準確度與推論效能取得一個權衡。對於問題與資料了解也很重要,才能依據要被解決的事務對症下藥。AI落地往往會發生一些窒礙難行問題產生,例如真實數據會有數據飄移問題、少樣本問題、資料標籤不易...等議題也是資料科學家應該關注的。
全民瘋AI系列的進階篇「揭開黑箱模型:探索可解釋人工智慧」。若對XAI技術有興趣的讀者們可以參考最新的鐵人賽系列文章哦!
2023更新 by 10


 iThome鐵人賽
iThome鐵人賽